

|
|
1.IntroductionFunctional near-infrared spectroscopy (fNIRS) measures the changes in cerebral hemodynamics and oxygenation by radiating weak visible or near-infrared light into the head and detecting the light reflected back (scattered) from another position.1–5 fNIRS has been applied to obtain two-dimensional topographical images of the changes in brain hemodynamics and oxygenation.6,7 All over the world, fNIRS systems have been used in more and more situations,8 such as in neuroimaging research9,10 and medical purposes,11–14 especially for measuring the brain activity of infants and children15–20 and for creating wearable equipment,21,22 because they have a high level of safety23,24 and require few constraints. One of the limitations of fNIRS is the potential effect of the extracerebral tissue on the signal. It was reported that an fNIRS signal can be contaminated by extracerebral signals.25–29 It has also been reported that the regional cerebral oxygen saturation is affected by extracranial contamination.30,31 Another issue concerning extracerebral effects is the interference of systemic hemodynamics on fNIRS signals.32,33 This is often referred to as broadly distributed signals caused by heart rate, blood pressure, and respiration. In other words, it is attributed to the effect of measuring systemically circulating blood. Systemic interference is included both in extracerebral and cerebral signals, so a signal originating from cerebral tissue may include a systemic contribution. Extracerebral veins have also been shown to affect fNIRS signals as a task-related systemic contribution.34 To deal with the above-described interference issues, various methods have been proposed.10 The validity of these methods, however, was confirmed by making certain assumptions, namely (expected) waveforms,35,36 contrast-to-noise ratio,37 and correlation with laser-Doppler signals.38,39 Few studies, however, have verified such methods by spatial analysis using simultaneous measurement by fNIRS and functional magnetic resonance imaging (fMRI). On the other hand, for providing higher spatial resolution, diffuse optical tomography using high-density probe arrangements has been proposed,40,41 and this technique was found to be consistent with nonsimultaneous fMRI. Although general consistency between fNIRS and fMRI has been reported,42–45 neither technique used multidistance optodes, and the purpose of these studies did not include the validation of methods for removing scalp effects. Through a concurrent multimodality study with fMRI and laser-Doppler flowmetry (LDF), a deep/shallow discrimination method can be validated from the spatial and temporal aspects. That kind of confirmation is highly valuable for the practical use of fNIRS with multidistance probes. Accordingly, in the present study, we tried to validate a method with multiple-distance probes and independent component analysis (ICA)38 to discriminate between the scalp and cerebral effects on the fNIRS signal using concurrently measured fMRI and LDF signals. 2.Materials and Methods2.1.ParticipantsA total of 12 healthy adult males (mean age: 37.7 years; age range: 30 to 48 years) participated in measurements by simultaneous fNIRS with multidistance probes [with source-detector (S-D) distances of 15 (or 16) and 30 mm], fMRI, and LDF. All participants gave written informed consent to the study protocol, which was approved by the Ethical Committee of the Faculty of Medicine, the University of Tokyo [No. 3156-(2)]. None of the participants had a medical history of psychiatric or neurological illness or serious head injury, and none of them had a history of psychotropic drug use. 2.2.Data Acquisition2.2.1.Functional near-infrared spectroscopyAn optical topography system (ETG-4000, Hitachi Medical Corporation, Japan) was used for the fNIRS measurements. The light sources consisted of continuous laser diodes with two wavelengths, 695 and 830 nm. The transmitted light (detected with avalanche photodiodes) was sampled every 100 ms. A multidistance measurement (namely 15-, 16-, and 30-mm S-D distances) was conducted with 16 light sources and 16 detectors. Two probe holders were placed for covering the left prefrontal cortex and the left somatosensory or motor cortex. Ten-millimeter-thick low-elastic rubber sheets were used for holding optical-fiber probes. On the optical fiber probes for a 15-mm S-D distance, optical filters were used for attenuating optical intensity. In total, 22 channels and 15 channels were measured for S-D 30 and 15 (or 16) mm, respectively. The channel arrangement and appearance of the probe holders used for the fNIRS measurements are shown in Fig. 1. To mark the optical-probe positions, vitamin-E tablets were placed on the probe holders [Fig. 1(a)]. The left one of the probe holders described in Fig. 1(a) is placed on the left prefrontal position, and the right one is placed on the left parietal position. The positions of the (21) vitamin-E tablets used as markers are shown by yellow ellipses. White squares indicate the positions of S-D 30-mm measurement channels [Fig. 1(b)]. Red squares indicate the positions of S-D 15- and 16-mm measurement channels [Fig. 1(c)]. A photograph of the probe holder worn by a representative participant is shown in Fig. 1(d), left, and a corresponding T1-weighted image with vitamin markers is shown in Fig. 1(d), right. Fig. 1Channel arrangement and appearance of probe holders for functional near-infrared spectroscopy (fNIRS) measurements: (a) Positions of sources, detectors, and vitamin-E markers. Left part is placed on left prefrontal position and right part is placed on left parietal position. Positions of 21 vitamin-E tablets used as markers are shown by yellow ellipses. (b) Positions of measurement channels with 30-mm source-detector (S-D) distance. (c) Positions of measurement channels with 15- and 16-mm S-D distances. The dotted ellipses indicate the channel groups for each S-D 30-mm channel. (d) Photograph of a probe holder worn by a representative participant (left) and the corresponding T1-weighted image with vitamin markers (right). 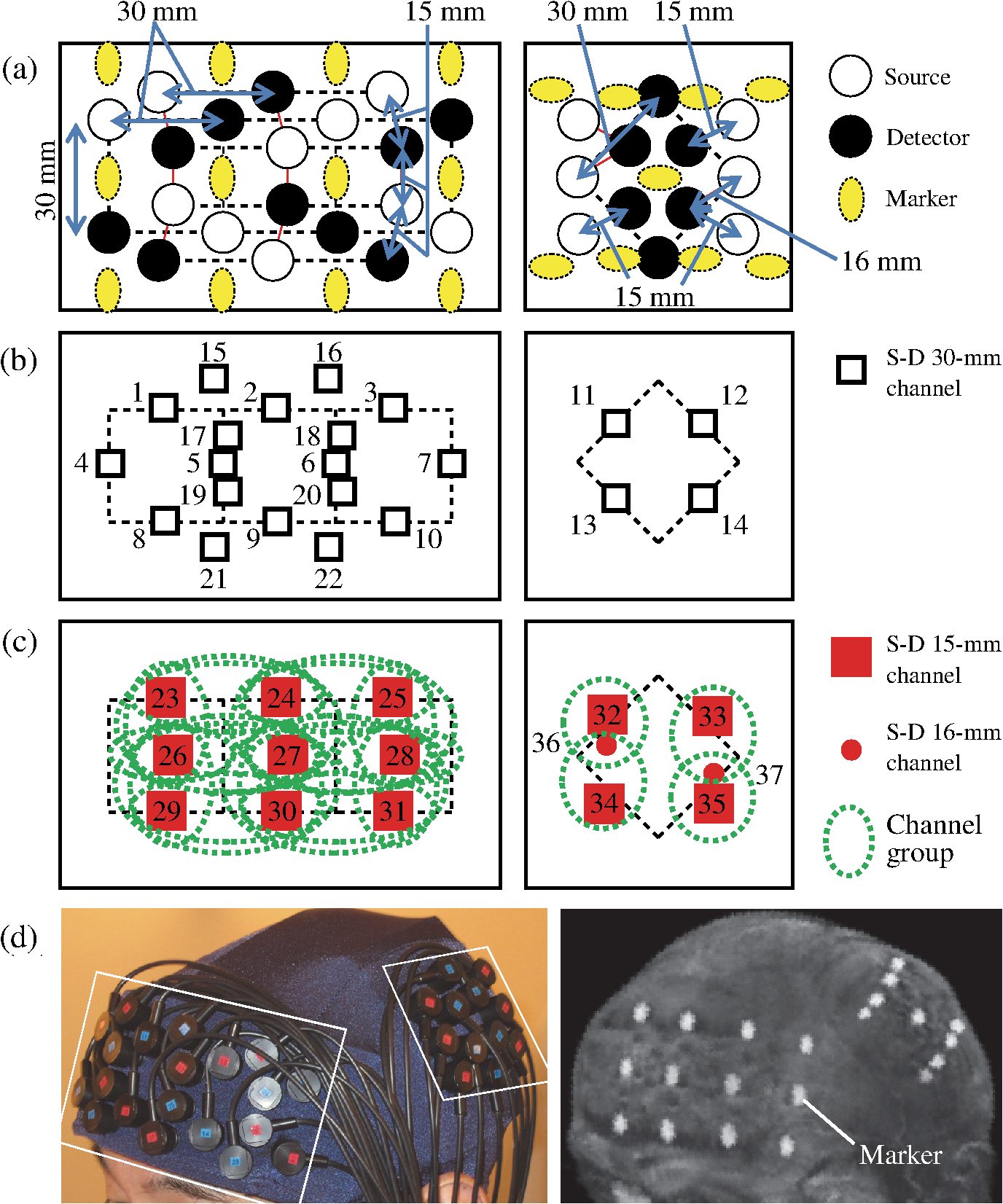 2.2.2.Magnetic resonance imagingMRI was performed with a Philips Achieva 3.0T TX system (Philips Medical Systems, The Netherlands) with a 32-channel SENSE head coil. A total of 130, 175, and 180 T2*-weighted gradient-echo echo-planar images (EPIs) were acquired while a participant underwent a single session of the verbal-fluency task (VFT), working-memory task (WM), and finger-tapping task (TAP) (described below), respectively. The parameters used for acquiring EPIs are listed in Table 1. A single EPI volume consisted of 30 4-mm-thick (for VFT) or 35 3-mm-thick (for WM and TAP) axial slices interspaced by a 1-mm gap, covering the entire brain. Other imaging parameters included repetition time (TR) of 4000 ms (for VFT) or 2500 ms (for WM and TAP), echo time (TE) of 30 ms, flip angle (FA) of 80 deg, field-of-view (FOV) of , and matrix size of . The total measurement time (number of ) was set to more than the total task duration (). For all the tasks employed, the initial four scans were discarded to allow for the T1-equilibration effects. Thus, the numbers of scans listed in Table 1 are those excluding the number of those “dummy” scans. Within the numbers of scans, the final eight scans in WM and the first one scan in TAP were not used to match the data size of blood oxygenation level–dependent (BOLD) signal to that of fNIRS signal. Following the functional imaging, a B0 field map was acquired by keeping the same head position (35 4-mm-thick axial slices, TR of 20 ms, and TEs of ). The B0 field map was later used to reduce the image distortion caused by inhomogeneity in the magnetic field. Further, for anatomically identifying activated regions in the brain, a T1-weighted structural image was obtained (FOV: ; in-place resolution: ; 301 contiguous sagittal slices with thickness of 0.6 mm; TR: 7.4 ms; TE: 3.4 ms; and FA: 8 deg). Table 1Parameters used for acquisition of echo-planar image (EPI).
Note: VFT, verbal-fluency task; WM, working-memory task; TAP, finger-tapping task; FOV, field-of-view; TR, repetition time; TE, echo time; FA, flip angle. 2.2.3.Laser-Doppler flowmetrySkin blood flow was measured with an LDF (MICROFLO DSP, Oxford Optronix Ltd., UK) equipped with two surface probes. One was attached to the skin, centered between the eyebrows (channel 1), and the other was attached to the left temple (channel 2). The LDF analog output was converted into a digital signal by an analog-to-digital converter (NR-2000, Keyence Corporation, Japan). 2.3.TasksThe tasks performed in this study were a VFT,11,12 a verbal WM,46–48 and a TAP.49 Target areas for each task were set as Brodmann areas (BAs) 9, 10, 44, 45, and 46 for VFT, BA 46 for WM, and BAs 1, 2, 3, 4, and 40 for TAP. In the VFT, each trial consisted of a 40-s pretask control period, a 60-s task period, and a 70-s post-task control period. During each task period (60 s), the participants were requested to verbalize as many words as possible that began with a Japanese character enunciated through headphones every 20 s (three characters per trial). The characters, which were enunciated randomly, included /a/, /to/, /na/, /i/, /ki/, /se/, /o/, /ta/, and /ha/. During each control period, the participants were requested to repeatedly verbalize the five Japanese vowels (/a/, /i/, /u/, /e/, and /o/).11 The sequence was repeated for three trials. Speech during fMRI scanning might cause movement artifacts in BOLD signals; therefore, in this study, we adopted a method to acquire all slices from the volume in the first period of the relatively longer TR and to make the remaining period a “no-sound” period.50,51 The acquisition time (TA) (for 30 slices) was set to 1205 ms and participants produced all speech (words and vowels) during the no-sound period of TRs, i.e., . We confirmed that this duration was sufficient for all the participants to complete their articulation. This is the point that is different from the conventional VFT sequence. The temporal differences among slices exist within TA (1205 ms) and were not corrected in the present study. This is because the temporal change in the BOLD signal is several times longer than the time scale of the present TA, for which the benefit of correction can be minimal. The WM and the TAP are described in our previous paper.52 Briefly, in the WM (which had an identical delayed-response paradigm), each trial started with a 1.5-s presentation of the target stimuli (“target” hereafter) on a PC display screen, which was followed by a delay of 7 s. A probe stimulus (“probe” hereafter) was then presented for 2.0 s or until the participant responded. The participant responded by pressing a button on a handheld pad connected to the PC. The button-pressing time was recorded. In the WM, one or four Japanese hiragana characters were presented as the target and a Japanese katakana character was presented as the probe. The participants were instructed to judge whether the character presented as the probe corresponded to any of the target characters and then press the appropriate button. The intervals between the probe onset and the following target onset in the next trial were 24 s. Only a central fixation cross was presented during the interval and delay periods. In addition, a visual cue (changing the color of the fixation cross) was presented for 0.5 s prior to trial onset. Auditory cues (1000- and 800-Hz pure tones of 100-ms duration) were presented at the onset of the visual cue and probe, respectively. One-item and four-item conditions were presented in a pseudorandom order. The sequence was repeated for 16 trials (eight trials for the one-item condition and eight trials for the four-item condition). In the TAP, the tip of the thumb was touched with the tip of each finger in serial order (forefinger, second finger, third finger, little finger, third finger, second finger, forefinger). On the computer screen, the color of the right or left arm of the fixation cross “+” changed alternately between black and yellow at 3.3 Hz (duration of each color: 150 ms). The participants were requested to tap the finger of the left/right hand when the direction of the yellow arm was left/right, synchronized with the presentation timing of the yellow arm. The task duration was 15 s, and there was a 25-s rest period between tasks. The right- and left-finger tapping tasks were repeated five times (10 trials in total). After the initial dummy scans, analog pulse signals indicating fMRI scanning timings were sent from the MRI system to a PC, in which a software package (E-Prime, Psychology Software Tools, Inc., USA) was used to present visual and auditory stimuli to synchronize the stimuli presentation to the fMRI scanning and to send serial commands to the fNIRS system for recording the time of the stimuli presentation. 2.4.Data AnalysisMATLAB (The MathWorks, Inc., USA) was primarily used for the analysis. A flowchart of the data analysis is shown in Fig. 2. 2.4.1.Preprocessing of functional near-infrared spectroscopy and laser-Doppler-flowmetry signalsThe oxy- and deoxy-Hb changes were calculated by using the optical density change of 695- and 830-nm light in accordance with the modified Beer-Lambert law.7,53 As the preprocessing for the fNIRS data analysis, a low-pass filter (VFT: , WM: , TAP: ) was applied for suppressing the pulse signals and a high-pass filter (VFT: , WM: , TAP: , inverse number of two times of each trial period) was applied for suppressing the low-frequency fluctuation. Low-pass and high-pass filters with the same cutoff frequencies described above were applied to the LDF signals. 2.4.2.Discrimination between deep- and shallow-layer functional near-infrared spectroscopy signalsA method for discriminating between deep and shallow signals included in original oxy- and deoxy-Hb fNIRS signals obtained with multidistance optodes by using the dependence of independent component amplitude (weight) on S-D distance, referred to as multidistance ICA (MD-ICA), was used.38,54 Briefly, a time-delayed decorrelation (TDD)-ICA55,56 was applied for obtaining independent components for each “channel group” that includes one S-D 30-mm channel and the nearest one to four S-D 15- or 16-mm channels. Channel groups for execution of TDD-ICA are listed in Table 2. They are also described in Fig. 1(c). For each independent component, the deep/shallow contribution ratios were calculated from the dependence of the signal amplitude (i.e., weight of component) on S-D distance. The deep and shallow subcomponents were then calculated by multiplying the independent components by deep/shallow contribution ratios. At this time, the original independent component is the sum of the deep and shallow subcomponents. Deep and shallow signals are then reconstructed using the sum of the subcomponents of all independent components. Delay times as a TDD-ICA parameter were set to 80, 16, and 21 s for VFT, WM, and TAP, respectively, which are about half the time of the block period [i.e., task plus control (rest) period]. Table 2Channel groups for execution of time-delayed decorrelation independent component analysis (TDD-ICA).
As for the MD-ICA method, it is assumed that the partial optical path length of the deep layer linearly increases as the S-D distance increases, while that of the shallow layer does not change. This assumption is supported by several research works.57–60 Moreover, it was assumed that the fNIRS signals at each S-D distance can be expressed by the linear sum of hemoglobin change signals, which are proportional to the partial optical path length at the scalp and gray matter (GM).61 To apply the MD-ICA method to fNIRS data, at least two kinds of S-D distance () are necessary. indicates the shortest S-D distance at which the detected light has sensitivity to absorption change in GM and is assumed to be 10.5 mm in adults.38 Moreover, the channels in the same channel group should be close enough to each other. In this study, the center-to-center distance (center means midpoint between source and detector) between the long-distance (S-D 30 mm) and the short-distance (S-D 15 or 16 mm) channels was then set to be within 19 mm. The threshold of the center-to-center distance (19 mm) was set according to the previous study,38 where we confirmed that the MD-ICA method successfully worked even when the center-to-center distance was 16.8 mm. The maximal center-to-center distance in the present case is 18.4 mm (e.g., between channels 15 and 24). The difference between 16.8 and 18.4 mm is only 1.6 mm, and we then assumed that 18.4 mm was also valid for execution of MD-ICA. The deep- and shallow-layer contributions’ ratio for each channel was calculated by using the amplitude-weighted mean of contribution ratios. 2.4.3.Functional near-infrared spectroscopy activation channel and effect sizeThe activation channel of the fNIRS signal was chosen from BAs 9, 10, 44, 45, and 46 for VFT, BA 46 for WM, and BAs 1, 2, 3, 4, and 40 for TAP. The BA number was determined62 for each projection point from the Montreal Neurological Institute (MNI) coordinates. The activation channel for each participant was determined by the effect size (Cohen’s ) of the original fNIRS signal. The effect size is the amplitude difference between the mean of the task period [mean (task)] and that of the control period [mean (control)] divided by the pooled standard deviation (). The equation for the effect size is expressed as where and denote the vectors of raw Hb signals in the task and control periods, respectively; and denote the numbers of time points for and ; and and denote the temporal means of and , respectively.52 For the calculation of and , no temporal offset for the transient phase was set. For calculation of , the task periods of the four-item condition for WM and right-hand tapping condition for TAP of all repetitions were used. For calculation of , the periods of 30, 5, and 5 s before task onset were used for VFT, WM, and TAP, respectively.In this study, the channels at which the effect size of oxygenated hemoglobin (oxy-Hb) is over 0.2 and that of deoxygenated hemoglobin (deoxy-Hb) is under were first selected. After that, the channel at which the difference between the effect sizes of oxy- and deoxy-Hb in the target areas for each task is maximal was selected as an activation channel. The channels at which the absolute amplitude of the deep signal is over 0.6 mM·mm in the entire time span have been removed as noise channels. 2.4.4.Spatially weighted blood oxygenation level–dependent signalThe photon-diffusion region (sensitivity map) expressed in voxel coordinates for each channel of the fNIRS system was calculated for each participant. A gray matter (GM)-BOLD signal was calculated from a spatially weighted sum of BOLD signals at voxels in the photon-diffusion region that is included in the segmented GM region. The processing for obtaining a GM-BOLD signal is described in detail in our previous study.52,63 The photon-diffusion region and the GM-BOLD signal were calculated only for S-D 30-mm pairs. Short-distance channels were used for calculating deep and shallow signals of S-D 30-mm channels by the MD-ICA method. 2.4.5.Methods for evaluating discrimination performanceThe MD-ICA method separates the fNIRS signal on the basis of signal depth (deep or shallow). As references for a shallow optical signal, skin blood flow (LDF signals) was measured. The following two methods were used to evaluate the performance of the MD-ICA method. Correlation between fNIRS and LDF signalsThe correlation coefficients of original, deep, and shallow signals versus the LDF signal were calculated by the way used in some literature,38,39,64 whereas Takahashi et al.29 calculated the temporally integrated LDF signal (blood volume) to compare it with fNIRS signal because, in principle, the integrated LDF signal may relate more to the fNIRS signal than the direct LDF signal (blood flow) does. It was expected that the LDF signal had a higher correlation coefficient with the shallow signal than that with the deep one. For calculating means and standard deviations of correlation coefficients between fNIRS and LDF signals, all S-D 30-mm channels (22 channels in total) of fNIRS and both LDF channels 1 and 2 were used. It has been reported that the fNIRS signal obtained with a short-distance probe (i.e., a surface fNIRS signal) is highly correlated with the LDF signal.38,64 The sign of the deoxy-Hb signal was inverted. While the total-Hb signal (oxy-Hb + deoxy-Hb) is more related to the blood flow signal than oxy- and deoxy-Hb signals in general, oxy- and deoxy-Hb signals were used for the correlation analysis with LDF signals because the present study focused on deep and shallow separation and the contribution ratio depends on Hb types (oxy/deoxy).38 A two-sample -test was used to compare the correlation coefficients among signal depths (original/deep/shallow) for each task and the Hb type with a Bonferroni correction for three comparisons. Correlation between fNIRS and GM-BOLD signalsThe correlation coefficients for the waveforms of the separated fNIRS signals and the GM-BOLD signals were analyzed, and the correlation coefficients for deep fNIRS and GM-BOLD signals were expected to be larger than those for shallow fNIRS and GM-BOLD signals. To investigate this expectation, a three-way () analysis of variance (ANOVA) was applied to the correlation coefficients for the fNIRS and GM-BOLD signals. The sign of the deoxy-Hb signal was inverted. The fNIRS data were down-sampled to match the fMRI data used for the correlation analysis. Some studies using concurrent fNIRS and fMRI measurements focused on the BOLD-significant (i.e., activation) area.43,65 In this analysis, on the other hand, the significance of the task-related change in GM-BOLD signal was not calculated for each channel and all the channels in the target areas for each task were used, because the significance of the change in GM-BOLD signal is not directly related to deep/shallow separation performance. 3.Results3.1.Functional Near-Infrared Spectroscopy Channel PositionsThe representative positions of each fNIRS channel were determined from the closest point on the brain surface to the midpoint of the source and detector positions. The BA number62 for each channel was determined for each participant in accordance with the determination of fNIRS channel positions in the MNI space (Table 3). Table 3Estimated location of each near-infrared spectroscopy (NIRS) channel on normalized brain image. Mean and standard deviation (SD) of Montreal Neurological Institute (MNI) coordinates across participants and corresponding Brodmann area (BA) numbers are shown for each channel. Percentage of participants by BA number is shown in parentheses.
3.2.Grand-Average at Activation ChannelGrand-average continuous signals of fNIRS (original, deep, and shallow), GM-BOLD, and LDF signal changes (channel 2) at the activation channel obtained during VFT are shown in Fig. 3. Standard errors at each time point are displayed as translucent patches. Vertical solid and dashed lines indicate task onset and end timings, respectively. A task-related response during VFT was obtained for each signal. Fig. 3Grand average of continuous data of fNIRS (original, deep, and shallow) and gray matter blood-oxygenation-level dependent (GM-BOLD) signals for activation channel, and laser-Doppler-flowmetry (LDF) signal changes (channel 2) obtained during verbal fluency task (VFT). Translucent patches indicate the standard error at each time point. Vertical solid and dashed lines indicate task onset and end timings, respectively. (a) Original signal; (b) deep signal; (c) shallow signal [oxy-Hb (solid line), deoxy-Hb (dashed line)]; (d) GM-BOLD signal change (%); and (e) LDF signal change (arb. unit). 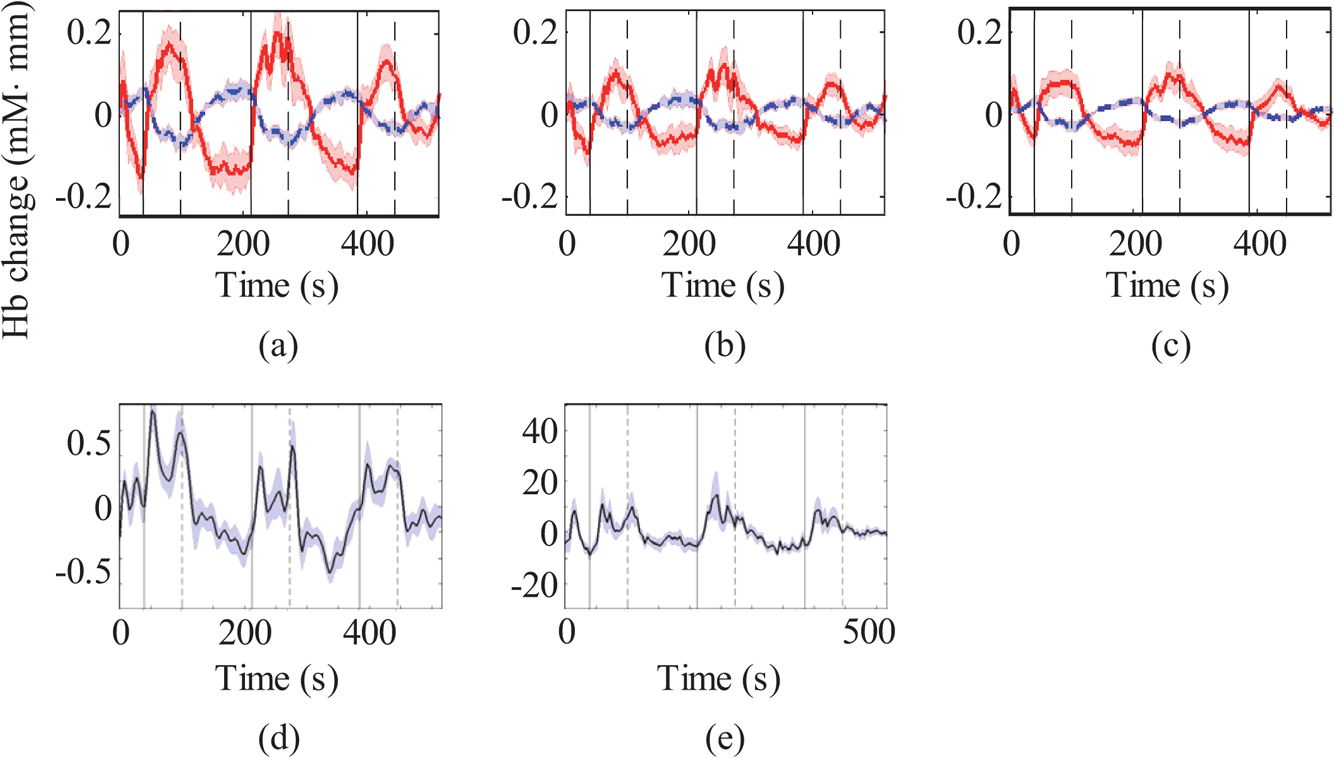 3.3.Correlation with Laser-Doppler-Flowmetry SignalsCorrelation coefficients (Fisher’s -transformation converted from Pearson’s correlation coefficient ) for oxy- and deoxy-Hb signals (original, deep, and shallow) and LDF signals (including channels 1 and 2) during performance of VFT, WM, and TAP are shown in Fig. 4. Error bars indicate the standard deviations. Single (*) and double (**) asterisks denote the statistical significance at and 0.01 (corrected for multiple comparisons), respectively. Fig. 4Correlation coefficients (Fisher’s ) between oxy- and deoxy-Hb signals (original, deep, and shallow) and LDF signal (including both channels 1 and 2) during a verbal fluency task (VFT), a working memory task (WM), and a finger tapping task (TAP). Error bars indicate the standard deviations. Single (*) and double (**) asterisks denote the statistical significance at and 0.01 (corrected for multiple comparisons), respectively. 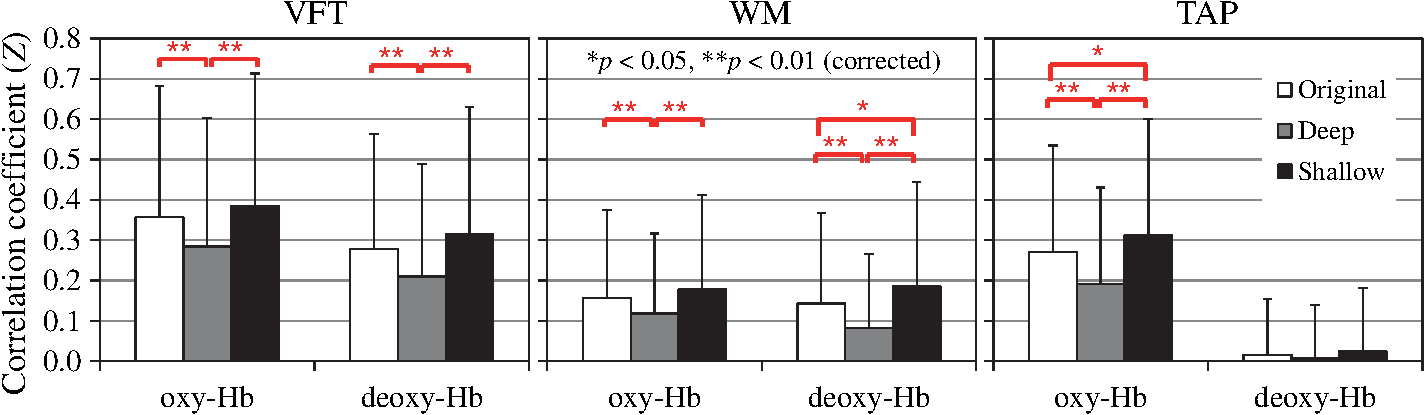 3.4.Analysis of Variance of Correlation between Functional Near-Infrared Spectroscopy and Gray Matter Blood Oxygenation Level–Dependent SignalsCorrelation coefficient (Fisher’s ) for the spatially weighted GM-BOLD signals and the fNIRS signals (deep and shallow signals of oxy- and deoxy-Hb) for the three tasks is shown in Fig. 5. All the channels in the target areas for each task were used. Figures 5(a) and 5(b) show the results for oxy- and deoxy-Hb, respectively. Error bars indicate the standard deviations. A three-way ANOVA [signal depth (deep/shallow) × Hb kind (oxy/deoxy) × task (VFT/WM/TAP)] indicates that the main effect of the separated fNIRS signal depth on the signal correlation is significant [, ] and that the interactions between the three effects are not significant. These results show that the mean of the correlation coefficients of the deep signal (mean: ) was significantly higher than that of the shallow signal (mean: ). Fig. 5Correlation coefficients (Fisher’s ) for (a) fNIRS oxy-Hb (deep and shallow) and spatially weighted GM-BOLD signals in target areas, and for (b) fNIRS deoxy-Hb (deep and shallow) and spatially weighted GM-BOLD signals in target areas during a VFT, a WM, and a TAP. Error bars indicate the standard deviations. The sign of deoxy-Hb signal is inverted. For any individual task, no significant differences were found between the correlations of deep and shallow fNIRS and GM-BOLD signals. 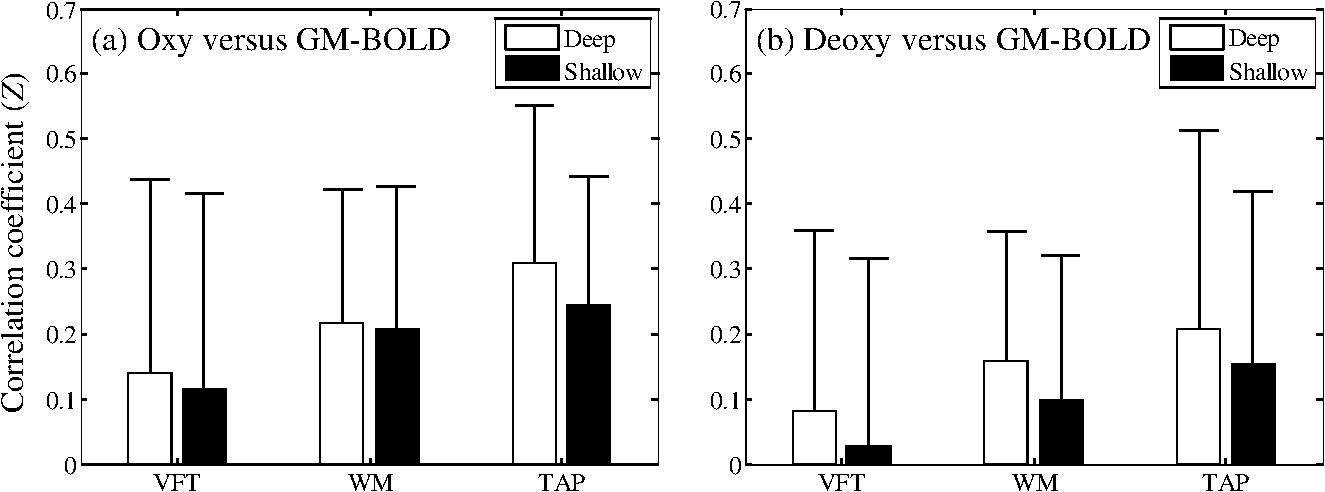 3.5.Deep-Layer Pooled Contribution Ratio Obtained by Multidistance Independent Component AnalysisMeans and standard deviations of deep-layer pooled contribution ratio (%) for activation channels are listed in Table 4. Although the deep-layer pooled contribution ratios are a little lower than those reported in a previous study,38 over half of the contribution of Hb signal to the fNIRS signals is originated from the deep layer, especially for oxy-Hb. Table 4Means and standard deviations of deep-layer pooled contribution ratio (%) at activation channels.
4.Discussion4.1.Correlations between Functional Near-Infrared Spectroscopy and Laser-Doppler-Flowmetry SignalsThe correlations between the fNIRS and LDF signals (shown in Fig. 4) are very similar to those obtained in a previous study38 that showed the correlation coefficients for deep fNIRS and LDF signals are significantly lower than those for shallow fNIRS and LDF signals. The correlation coefficient between deoxy-Hb and LDF signals under the TAP condition was extremely low. That was possibly because the deep-layer pooled contribution ratio of deoxy-Hb under the TAP condition was relatively high (Table 4) in the present study. The low correlation between deoxy-Hb and skin blood flow can be caused by the low contribution of the shallow signal. It should be noted that we did not temporally integrate the LDF signal, but the integrated LDF signal can be more correlated with fNIRS signal when a proper integration time is selected.29 From the aspect of correlation between fNIRS and LDF signals, it was shown that the fNIRS signals were reasonably divided into signals with either higher or lower correlations with the LDF signal. It should be noted that during the finger-tapping task, the LDF signal had a higher correlation with the shallow fNIRS signal than that with the deep fNIRS signal, even if the target channels were located mainly in somatosensory or motor areas (BAs 1, 2, 3, 4, and 40) far from the LDF probes (attached on the forehead or temple). The result suggests that the LDF signal correlates with the shallow fNIRS signal in the broad area during the finger-tapping task. 4.2.Correlation between Deep Functional Near-Infrared Spectroscopy Signals and Gray Matter Blood Oxygenation Level–Dependent SignalsThe mean of the correlation coefficients of the deep signal was significantly higher than that of the shallow signal. This is partly because deep (brain) and shallow (scalp) tissue layers are anatomically governed by different blood vessel systems (internal or external carotid artery). Different correlation coefficients for the fNIRS and the GM-BOLD signals would, therefore, be expected, i.e., the deep fNIRS signal should have stronger correlation with the GM-BOLD signal than that between the shallow fNIRS and the GM-BOLD signals. From this point of view, the results of the correlation between deep fNIRS and GM-BOLD signals (Fig. 5) showed that the MD-ICA method successfully separates fNIRS signals into deep and shallow signals that have higher and lower correlations, respectively, with spatially weighted GM-BOLD signals. Deep and shallow signals can be similar as a result of MD-ICA method. The high correlation between deep and shallow signals was also obtained in previous studies.38,54 This can happen because the same independent components are commonly used for reconstructing deep and shallow signals, and the systemic signals did not be removed in order to quantify the contributions of deep and shallow signals. If the contributions of components that included both deep and shallow signals are almost the same, then the correlations of the shallow and deep signals with the GM-BOLD would be almost equivalent. In the present case, however, different correlations were obtained. This means that deep and shallow signals were different enough from each other to evaluate the separation performance. Although mean deep and shallow signals seem very similar, as shown in Fig. 3 for example, individual deep and shallow signals are different and have different correlations with LDF or GM-BOLD signals. 4.3.Deep-Layer Contribution Ratio Obtained by Multidistance Independent Component AnalysisIt should be noted that the MD-ICA method quantifies the contribution ratios of both deep and shallow layers, but the ratios include the effect of systemic interference because the MD-ICA method discriminates fNIRS signals on the basis of signal depth only. Even if the deep-layer pooled contribution ratio is high, for example, it is possible that the systemic contribution in the deep layer is dominant. It has been reported that there is interindividual variability in the correlation between the fNIRS signal and the scalp blood flow or mean blood pressure66 and that the systemic changes that also affect extracranial signals can lead to false positives in fNIRS signals.33 It should be noted that the effect of posture (sitting or supine) on the contribution of deep-layer tissue to fNIRS signal and its dependency on kind of task have not been investigated. Such an effect might cause the difference between the contribution ratios obtained in the current study and in a previous study. 4.4.LimitationsIn regard to the proposed deep-shallow separation method (MD-ICA method), the structural parameter was fixed for all participants and for all measurement channels. In this study, it was confirmed that the fixed parameter is effective, even in the case where the structural differences depending on individuals and positions within individuals are not considered and neither MRI structural data nor x-ray CT data are available. It should be noted that the deep- or shallow-tissue condition may be changed by changing the posture. The deep/shallow contribution ratio calculated in this study (i.e., supine posture) is not necessarily the same as that calculated for a sitting posture. The measurement area was limited to only prefrontal, somatosensory, and motor cortices on the left side of the head. Other areas should be covered by the proposed method, so occipital and temporal areas should be further investigated. All participants in this study were male; it would, therefore, be more helpful to validate the proposed method by using female participants. 5.ConclusionThough very few studies have validated a multidistance scalp-effect-removal method with concurrent fNIRS-fMRI measurement, this study shows that the previously proposed deep/shallow separation method (MD-ICA method) successfully separates fNIRS signals into “spatially” deep and shallow signals by comparing these signals with spatially weighed GM-BOLD and LDF signals. The result shows that the accuracy and reliability of the fNIRS signal will be greatly improved with the MD-ICA method. The correlation coefficients for shallow fNIRS and LDF signals were larger than those for deep fNIRS and LDF signals. This result is consistent with the results obtained in a previous study.38 This method needs only small numbers of probes [at least two middle-distance () channels], so it will easily contribute to broad area (e.g., whole head) brain-imaging studies using cost-effective equipment. AcknowledgmentsThe authors thank Mr. Tsuyoshi Miyashita, Dr. Hirokazu Tanaka, and Dr. Eisuke Sakakibara for their assistance with the experiments, Dr. Daisuke Suzuki, Mr. Michiyuki Fujiwara, and Mr. Shingo Kawasaki for providing technical assistance, Dr. Akiko Obata and Dr. Ryuta Aoki for their helpful comments on the experimental design, and Dr. Shizu Takeda and Dr. Atsushi Maki for their general support. This study was supported by Grants-in-Aid for Scientific Research on Innovative Areas [Nos. 23118001 and 23118004 (Adolescent Mind & Self-Regulation) to KK, No. 32118003 to MF, and Comprehensive Brain Science Network to KK], a Grant-in-Aid for Young Scientists (B) (Nos. 23791309 and 26860914) to RT, a Grant-in-Aid for Scientific Research (B) (No. 23390286) to MF, and a Grant-in-Aid for Challenging Exploratory Research (No. 22659209) to MF from the Ministry of Education, Culture, Sports, Science and Technology of Japan (MEXT). A part of this study was also the result of the “Development of Biomarker Candidates for Social Behavior” interdisciplinary project carried out under the Strategic Research Program for Brain Sciences by MEXT. This study was also supported in part by Health and Labor Sciences Research Grants (H23-seishin-ippan-002 to RT, YN, and MF; H25-seishin-jitsuyoka-ippan-002 to KK; and H25-seishin-ippan-002 to MF) and Health and Labour Science Research Grant on the Practical Application of Medical Technology for Intractable Diseases and Cancer: New development of medical technology for the diagnosis and treatment of psychiatric diseases and cancer by construction of virtual mega-hospital for clinical trials to MF from the Ministry of Health, Labour and Welfare, and Intramural Research Grant for Neurological and Psychiatric Disorders (No. 24-1 and 23-10 to MF and 26-3 to MF and KK) from the National Center for Neurology and Psychiatry. Conflict of interest. Hitachi Medical Corporation provided a material support [temporary rental of an fNIRS (Optical Topography) ETG-4000 system] for this study. ReferencesB. Chanceet al.,
“Cognition-activated low-frequency modulation of light absorption in human brain,”
Proc. Natl. Acad. Sci. U. S. A., 90
(8), 3770
–3774
(1993). http://dx.doi.org/10.1073/pnas.90.8.3770 PNASA6 0027-8424 Google Scholar
Y. HoshiM. Tamura,
“Detection of dynamic changes in cerebral oxygenation coupled to neuronal function during mental work in man,”
Neurosci. Lett., 150
(1), 5
–8
(1993). http://dx.doi.org/10.1016/0304-3940(93)90094-2 NELED5 0304-3940 Google Scholar
F. F. Jöbsis,
“Noninvasive, infrared monitoring of cerebral and myocardial oxygen sufficiency and circulatory parameters,”
Science, 198
(4323), 1264
–1267
(1977). http://dx.doi.org/10.1126/science.929199 SCIEAS 0036-8075 Google Scholar
T. Katoet al.,
“Human visual cortical function during photic stimulation monitoring by means of near-infrared spectroscopy,”
J. Cereb. Blood Flow Metab., 13
(3), 516
–520
(1993). http://dx.doi.org/10.1038/jcbfm.1993.66 JCBMDN 0271-678X Google Scholar
A. Villringeret al.,
“Near infrared spectroscopy (NIRS): a new tool to study hemodynamic changes during activation of brain function in human adults,”
Neurosci. Lett., 154
(1–2), 101
–104
(1993). http://dx.doi.org/10.1016/0304-3940(93)90181-J NELED5 0304-3940 Google Scholar
H. Koizumiet al.,
“Higher-order brain function analysis by trans-cranial dynamic near-infrared spectroscopy imaging,”
J. Biomed. Opt., 4
(4), 403
–413
(1999). http://dx.doi.org/10.1117/1.429959 JBOPFO 1083-3668 Google Scholar
A. Makiet al.,
“Spatial and temporal analysis of human motor activity using noninvasive NIR topography,”
Med. Phys., 22
(12), 1997
–2005
(1995). http://dx.doi.org/10.1118/1.597496 MPHYA6 0094-2405 Google Scholar
D. A. Boaset al.,
“Twenty years of functional near-infrared spectroscopy: introduction for the special issue,”
NeuroImage, 85
(1), 1
–5
(2014). http://dx.doi.org/10.1016/j.neuroimage.2013.11.033 NEIMEF 1053-8119 Google Scholar
M. FerrariV. Quaresima,
“A brief review on the history of human functional near-infrared spectroscopy (fNIRS) development and fields of application,”
NeuroImage, 63
(2), 921
–935
(2012). http://dx.doi.org/10.1016/j.neuroimage.2012.03.049 NEIMEF 1053-8119 Google Scholar
F. Scholkmannet al.,
“A review on continuous wave functional near-infrared spectroscopy and imaging instrumentation and methodology,”
NeuroImage, 85
(1), 6
–7
(2014). http://dx.doi.org/10.1016/j.neuroimage.2013.05.004 NEIMEF 1053-8119 Google Scholar
T. Sutoet al.,
“Multichannel near-infrared spectroscopy in depression and schizophrenia: cognitive brain activation study,”
Biol. Psychiatry, 55
(5), 501
–511
(2004). http://dx.doi.org/10.1016/j.biopsych.2003.09.008 BIPCBF 0006-3223 Google Scholar
R. Takizawaet al.,
“Neuroimaging-aided differential diagnosis of the depressive state,”
NeuroImage, 85
(1), 498
–507
(2014). http://dx.doi.org/10.1016/j.neuroimage.2013.05.126 NEIMEF 1053-8119 Google Scholar
E. Watanabeet al.,
“Non-invasive assessment of language dominance with near-infrared spectroscopic mapping,”
Neurosci. Lett., 256
(1), 49
–52
(1998). http://dx.doi.org/10.1016/S0304-3940(98)00754-X NELED5 0304-3940 Google Scholar
S. Puet al.,
“Association between cognitive insight and prefrontal function during a cognitive task in schizophrenia: a multichannel near-infrared spectroscopy study,”
Schizophr. Res., 150
(1), 81
–87
(2013). http://dx.doi.org/10.1016/j.schres.2013.07.048 SCRSEH 0920-9964 Google Scholar
T. GrossmannM. H. Johnson,
“Selective prefrontal cortex responses to joint attention in early infancy,”
Biol. Lett., 6
(4), 540
–543
(2010). http://dx.doi.org/10.1098/rsbl.2009.1069 1744-9561 Google Scholar
F. Homaeet al.,
“Development of global cortical networks in early infancy,”
J. Neurosci., 30
(14), 4877
–4882
(2010). http://dx.doi.org/10.1523/JNEUROSCI.5618-09.2010 JNRSDS 0270-6474 Google Scholar
F. Homae,
“A brain of two halves: insights into interhemispheric organization provided by near-infrared spectroscopy,”
NeuroImage, 85
(1), 354
–362
(2014). http://dx.doi.org/10.1016/j.neuroimage.2013.06.023 NEIMEF 1053-8119 Google Scholar
Y. Minagawa-Kawaiet al.,
“Prefrontal activation associated with social attachment: facial-emotion recognition in mothers and infants,”
Cereb. Cortex, 19
(2), 284
–292
(2009). http://dx.doi.org/10.1093/cercor/bhn081 53OPAV 1047-3211 Google Scholar
G. Tagaet al.,
“Spontaneous oscillation of oxy- and deoxy-hemoglobin changes with a phase difference throughout the occipital cortex of newborn infants observed using non-invasive optical topography,”
Neurosci. Lett., 282
(1–2), 101
–104
(2000). http://dx.doi.org/10.1016/S0304-3940(00)00874-0 NELED5 0304-3940 Google Scholar
G. Tagaet al.,
“Brain imaging in awake infants by near-infrared optical topography,”
Proc. Natl. Acad. Sci. U. S. A., 100
(19), 10722
–10727
(2003). http://dx.doi.org/10.1073/pnas.1932552100 PNASA6 0027-8424 Google Scholar
H. Atsumoriet al.,
“Development of wearable optical topography system for mapping the prefrontal cortex activation,”
Rev. Sci. Instrum., 80
(4), 043704
(2009). http://dx.doi.org/10.1063/1.3115207 RSINAK 0034-6748 Google Scholar
T. Funaneet al.,
“Synchronous activity of two people’s prefrontal cortices during a cooperative task measured by simultaneous near-infrared spectroscopy,”
J. Biomed. Opt., 16
(7), 077011
(2011). http://dx.doi.org/10.1117/1.3602853 JBOPFO 1083-3668 Google Scholar
Y. Itoet al.,
“Assessment of heating effects in skin during continuous wave near infrared spectroscopy,”
J. Biomed. Opt., 5
(4), 383
–390
(2000). http://dx.doi.org/10.1117/1.1287730 JBOPFO 1083-3668 Google Scholar
M. Kiguchiet al.,
“Comparison of light intensity on the brain surface due to laser exposure during optical topography and solar irradiation,”
J. Biomed. Opt., 12
(6), 062108
(2007). http://dx.doi.org/10.1117/1.2804152 JBOPFO 1083-3668 Google Scholar
T. J. Germonet al.,
“Sensitivity of near infrared spectroscopy to cerebral and extra-cerebral oxygenation changes is determined by emitter-detector separation,”
J. Clin. Monit. Comput., 14
(5), 353
–360
(1998). http://dx.doi.org/10.1023/A:1009957032554 IJMCEJ 0167-9945 Google Scholar
S. Kohriet al.,
“Quantitative evaluation of the relative contribution ratio of cerebral tissue to near-infrared signals in the adult human head: a preliminary study,”
Physiol. Meas., 23
(2), 301
–312
(2002). http://dx.doi.org/10.1088/0967-3334/23/2/306 PMEAE3 0967-3334 Google Scholar
L. Minatiet al.,
“Intra- and extra-cranial effects of transient blood pressure changes on brain near-infrared spectroscopy (NIRS) measurements,”
J. Neurosci. Methods, 197
(2), 283
–288
(2011). http://dx.doi.org/10.1016/j.jneumeth.2011.02.029 JNMEDT 0165-0270 Google Scholar
P. Smielewskiet al.,
“Clinical evaluation of near-infrared spectroscopy for testing cerebrovascular reactivity in patients with carotid artery disease,”
Stroke, 28
(2), 331
–338
(1997). http://dx.doi.org/10.1161/01.STR.28.2.331 SJCCA7 0039-2499 Google Scholar
T. Takahashiet al.,
“Influence of skin blood flow on near-infrared spectroscopy signals measured on the forehead during a verbal fluency task,”
NeuroImage, 57
(3), 991
–1002
(2011). http://dx.doi.org/10.1016/j.neuroimage.2011.05.012 NEIMEF 1053-8119 Google Scholar
S. N. DavieH. P. Grocott,
“Impact of extracranial contamination on regional cerebral oxygen saturation: a comparison of three cerebral oximetry technologies,”
Anesthesiology, 116
(4), 834
–840
(2012). http://dx.doi.org/10.1097/ALN.0b013e31824c00d7 ANESAV 0003-3022 Google Scholar
H. Sørensenet al.,
“Cutaneous vasoconstriction affects near-infrared spectroscopy determined cerebral oxygen saturation during administration of norepinephrine,”
Anesthesiology, 117
(2), 263
–270
(2012). http://dx.doi.org/10.1097/ALN.0b013e3182605afe ANESAV 0003-3022 Google Scholar
S. B. ErdoğanM. A. YücelA. Akin,
“Analysis of task-evoked systemic interference in fNIRS measurements: insights from fMRI,”
NeuroImage, 87 490
–504
(2014). http://dx.doi.org/10.1016/j.neuroimage.2013.10.024 NEIMEF 1053-8119 Google Scholar
I. Tachtsidiset al.,
“False positives in functional near-infrared topography,”
Adv. Exp. Med. Biol., 645 307
–314
(2009). http://dx.doi.org/10.1007/978-0-387-85998-9 AEMBAP 0065-2598 Google Scholar
E. Kirilinaet al.,
“The physiological origin of task-evoked systemic artefacts in functional near infrared spectroscopy,”
NeuroImage, 61
(1), 70
–81
(2012). http://dx.doi.org/10.1016/j.neuroimage.2012.02.074 NEIMEF 1053-8119 Google Scholar
L. Gagnonet al.,
“Improved recovery of the hemodynamic response in diffuse optical imaging using short optode separations and state-space modeling,”
NeuroImage, 56
(3), 1362
–1371
(2011). http://dx.doi.org/10.1016/j.neuroimage.2011.03.001 NEIMEF 1053-8119 Google Scholar
R. B. SaagerN. L. TelleriA. J. Berger,
“Two-detector corrected near infrared spectroscopy (C-NIRS) detects hemodynamic activation responses more robustly than single-detector NIRS,”
NeuroImage, 55
(4), 1679
–1685
(2011). http://dx.doi.org/10.1016/j.neuroimage.2011.01.043 NEIMEF 1053-8119 Google Scholar
Q. ZhangE. N. BrownG. E. Strangman,
“Adaptive filtering to reduce global interference in evoked brain activity detection: a human subject case study,”
J. Biomed. Opt., 12
(6), 064009
(2007). http://dx.doi.org/10.1117/1.2804706 JBOPFO 1083-3668 Google Scholar
T. Funaneet al.,
“Quantitative evaluation of deep and shallow tissue layers’ contribution to fNIRS signal using multi-distance optodes and independent component analysis,”
NeuroImage, 85
(1), 150
–165
(2014). http://dx.doi.org/10.1016/j.neuroimage.2013.02.026 NEIMEF 1053-8119 Google Scholar
S. Kohnoet al.,
“Removal of the skin blood flow artifact in functional near-infrared spectroscopic imaging data through independent component analysis,”
J. Biomed. Opt., 12
(6), 062111
(2007). http://dx.doi.org/10.1117/1.2814249 JBOPFO 1083-3668 Google Scholar
A. T. Eggebrechtet al.,
“Mapping distributed brain function and networks with diffuse optical tomography,”
Nat. Photonics, 8
(6), 448
–454
(2014). http://dx.doi.org/10.1038/nphoton.2014.107 1749-4885 Google Scholar
D. K. Josephet al.,
“Diffuse optical tomography system to image brain activation with improved spatial resolution and validation with functional magnetic resonance imaging,”
Appl. Opt., 45
(31), 8142
–8151
(2006). http://dx.doi.org/10.1364/AO.45.008142 APOPAI 0003-6935 Google Scholar
D. A. BoasA. M. DaleM. A. Franceschini,
“Diffuse optical imaging of brain activation: approaches to optimizing image sensitivity, resolution, and accuracy,”
NeuroImage, 23
(Suppl 1), S275
–288
(2004). http://dx.doi.org/10.1016/j.neuroimage.2004.07.011 NEIMEF 1053-8119 Google Scholar
X. Cuiet al.,
“A quantitative comparison of NIRS and fMRI across multiple cognitive tasks,”
NeuroImage, 54
(4), 2808
–2821
(2011). http://dx.doi.org/10.1016/j.neuroimage.2010.10.069 NEIMEF 1053-8119 Google Scholar
F. B. Haeussingeret al.,
“Reconstructing functional near-infrared spectroscopy (fNIRS) signals impaired by extra-cranial confounds: an easy-to-use filter method,”
NeuroImage, 95 69
–79
(2014). http://dx.doi.org/10.1016/j.neuroimage.2014.02.035 NEIMEF 1053-8119 Google Scholar
S. Heinzelet al.,
“Variability of (functional) hemodynamics as measured with simultaneous fNIRS and fMRI during intertemporal choice,”
NeuroImage, 71
(1), 125
–134
(2013). http://dx.doi.org/10.1016/j.neuroimage.2012.12.074 NEIMEF 1053-8119 Google Scholar
R. Aokiet al.,
“Relationship of negative mood with prefrontal cortex activity during working memory tasks: an optical topography study,”
Neurosci. Res., 70
(2), 189
–196
(2011). http://dx.doi.org/10.1016/j.neures.2011.02.011 NERADN 0168-0102 Google Scholar
R. Aokiet al.,
“Correlation between prefrontal cortex activity during working memory tasks and natural mood independent of personality effects: an optical topography study,”
Psychiatry Res.: Neuroimaging, 212
(1), 79
–87
(2013). http://dx.doi.org/10.1016/j.pscychresns.2012.10.009 0925-4927 Google Scholar
H. Satoet al.,
“Correlation of within-individual fluctuation of depressed mood with prefrontal cortex activity during verbal working memory task: optical topography study,”
J. Biomed. Opt., 16
(12), 126007
(2011). http://dx.doi.org/10.1117/1.3662448 JBOPFO 1083-3668 Google Scholar
H. Satoet al.,
“Intersubject variability of near-infrared spectroscopy signals during sensorimotor cortex activation,”
J. Biomed. Opt., 10
(4), 044001
(2005). http://dx.doi.org/10.1117/1.1960907 JBOPFO 1083-3668 Google Scholar
S. Abrahamset al.,
“Functional magnetic resonance imaging of verbal fluency and confrontation naming using compressed image acquisition to permit overt responses,”
Hum. Brain Mapp., 20
(1), 29
–40
(2003). http://dx.doi.org/10.1002/(ISSN)1097-0193 HBRME7 1065-9471 Google Scholar
W. B. Edmisteret al.,
“Improved auditory cortex imaging using clustered volume acquisitions,”
Hum. Brain Mapp., 7
(2), 89
–97
(1999). http://dx.doi.org/10.1002/(ISSN)1097-0193 HBRME7 1065-9471 Google Scholar
H. Satoet al.,
“A NIRS-fMRI investigation of prefrontal cortex activity during a working memory task,”
NeuroImage, 83 158
–173
(2013). http://dx.doi.org/10.1016/j.neuroimage.2013.06.043 NEIMEF 1053-8119 Google Scholar
D. T. Delpyet al.,
“Estimation of optical pathlength through tissue from direct time of flight measurement,”
Phys. Med. Biol., 33
(12), 1433
–1442
(1988). http://dx.doi.org/10.1088/0031-9155/33/12/008 PHMBA7 0031-9155 Google Scholar
T. Funaneet al.,
“Greater contribution of cerebral than extracerebral hemodynamics to near-infrared spectroscopy signals for functional activation and resting-state connectivity in infants,”
Neurophotonics, 1
(2), 025003
(2014). http://dx.doi.org/10.1117/1.NPh.1.2.025003 2329-423X Google Scholar
J. F. Cardoso,
“Blind signal separation: statistical principles,”
Proc. IEEE, 86
(10), 2009
–2025
(1998). http://dx.doi.org/10.1109/5.720250 IEEPAD 0018-9219 Google Scholar
T. Katuraet al.,
“Extracting task-related activation components from optical topography measurement using independent components analysis,”
J. Biomed. Opt., 13
(5), 054008
(2008). http://dx.doi.org/10.1117/1.2981829 JBOPFO 1083-3668 Google Scholar
Y. FukuiY. AjichiE. Okada,
“Monte Carlo prediction of near-infrared light propagation in realistic adult and neonatal head models,”
Appl. Opt., 42
(16), 2881
–2887
(2003). http://dx.doi.org/10.1364/AO.42.002881 APOPAI 0003-6935 Google Scholar
A. Hirasawaet al.,
“Influence of skin blood flow and source-detector distance on near-infrared spectroscopy-determined cerebral oxygenation in humans,”
Clin. Physiol. Funct. Imaging,
(2014). http://dx.doi.org/10.1111/cpf.12156 CPFICA 1475-0961 Google Scholar
G. E. StrangmanQ. ZhangZ. Li,
“Scalp and skull influence on near infrared photon propagation in the Colin27 brain template,”
NeuroImage, 85
(1), 136
–149
(2014). http://dx.doi.org/10.1016/j.neuroimage.2013.04.090 NEIMEF 1053-8119 Google Scholar
T. YamadaS. UmeyamaK. Matsuda,
“Separation of fNIRS signals into functional and systemic components based on differences in hemodynamic modalities,”
PLoS One, 7
(11), e50271
(2012). http://dx.doi.org/10.1371/journal.pone.0050271 1932-6203 Google Scholar
T. Funaneet al.,
“Dynamic phantom with two stage-driven absorbers for mimicking hemoglobin changes in superficial and deep tissues,”
J. Biomed. Opt., 17
(4), 047001
(2012). http://dx.doi.org/10.1117/1.JBO.17.4.047001 JBOPFO 1083-3668 Google Scholar
C. RordenM. Brett,
“Stereotaxic display of brain lesions,”
Behav. Neurol., 12
(4), 191
–200
(2000). http://dx.doi.org/10.1155/2000/421719 BNEUEI 0953-4180 Google Scholar
A. Sassaroliet al.,
“Spatially weighted BOLD signal for comparison of functional magnetic resonance imaging and near-infrared imaging of the brain,”
NeuroImage, 33
(2), 505
–514
(2006). http://dx.doi.org/10.1016/j.neuroimage.2006.07.006 NEIMEF 1053-8119 Google Scholar
F. Alettiet al.,
“Deep and surface hemodynamic signal from functional time resolved transcranial near infrared spectroscopy compared to skin flowmotion,”
Comput. Biol. Med., 42
(3), 282
–289
(2012). http://dx.doi.org/10.1016/j.compbiomed.2011.06.001 CBMDAW 0010-4825 Google Scholar
A. Seiyamaet al.,
“Circulatory basis of fMRI signals: relationship between changes in the hemodynamic parameters and BOLD signal intensity,”
NeuroImage, 21
(4), 1204
–1214
(2004). http://dx.doi.org/10.1016/j.neuroimage.2003.12.002 NEIMEF 1053-8119 Google Scholar
I. Tachtsidiset al.,
“Investigation of frontal cortex, motor cortex and systemic haemodynamic changes during anagram solving,”
Adv. Exp. Med. Biol., 614 21
–28
(2008). http://dx.doi.org/10.1007/978-0-387-74911-2 AEMBAP 0065-2598 Google Scholar
BiographyTsukasa Funane is a researcher at Central Research Laboratory, Hitachi, Ltd., Japan. Since 2006, he has been a member of the research group working on optical topography, optical brain function monitoring technology based on near-infrared spectroscopy (NIRS). His main responsibilities include basic research on new measurement methods as well as hardware developments and their application to human brain study such as social cognitions. Hiroki Sato received his BA degree from International Christian University in 1998, his MA degree from the University of Tokyo in 2000, and his PhD degree from Keio University in 2006. He is currently a senior researcher of Central Research Laboratory, Hitachi, Ltd., and promotes the basic research to develop new applications of near-infrared spectroscopy (NIRS) in a wide range of fields. Noriaki Yahata received his BA degree from the University of Tokyo, Japan, in 1993 and his PhD degree from the State University of New York in 2001. He was an assistant professor at the Department of Pharmacology, Nippon Medical School (2005 to 2008) and the Department of Neuropsychiatry, the University of Tokyo (2009 to 2012). Currently, he is an assistant professor at the Department of Youth Mental Health, the University of Tokyo. His research interests include development of a neuroimaging-based biomarker for neuropsychiatric disorders. Ryu Takizawa received his BA degree in psychology in 1999 and his MD degree in 2003. After clinical training in the Department of Neuropsychiatry, the University of Tokyo, he received his PhD degree in medicine in 2010. Currently, he is an assistant professor at the Department of Neuropsychiatry, the University of Tokyo, and a Newton International fellow, Institute of Psychiatry, King’s College London. His interests include studies on clinical biomarkers and gene-environmental interplays in mental health from a life-course developmental perspective. Yukika Nishimura received her BA degree in experimental psychology from Keio University in 2001, her MSc degree in 2003, and her PhD degree in 2007 in medical science from Mie University, Japan. She was a research resident of the Japan Foundation for Neuroscience and Mental Health (2008 to 2011), and she is currently a project research associate in the Department of Neuropsychiatry at the University of Tokyo, Japan. Her research interest is the cognitive neuroscience of psychiatric disorders. Akihide Kinoshita received his MD degree from Tokyo Medical University in 2006 and his PhD degree from the University of Tokyo, Japan, in 2014. After clinical training in psychiatry at the Tokyo Metropolitan Bokutoh Hospital, he received clinical research training in neuroimaging in the Department of Neuropsychiatry, Graduate School of Medicine, University of Tokyo, Japan. He engages in research in the Department of Neuropsychiatry, the University of Tokyo, and his major research interest is neuroimaging in schizophrenia. Takusige Katura is a researcher at Central Research Laboratory, Hitachi, Ltd., Japan. Since 2001, he has been a member of the research group working on optical topography, optical brain function monitoring technology based on near-infrared spectroscopy (NIRS). His main responsibilities include basic research on new measurement methods as well as signal analysis and its application to human brain study such as social cognitions. Hirokazu Atsumori is a researcher in the Central Research Laboratory, Hitachi, Ltd., Japan. He has been working on the research and development of optical topography, a functional neuroimaging technique based on near-infrared spectroscopy, since 2002. He is now engaged in the development of a wearable and compact optical topography system for monitoring prefrontal cortex activities and its application to new research fields. Masato Fukuda received his MD degree in 1983 and his PhD degree in 1997 from the University of Tokyo, Japan. His professional achievements include being an assistant professor in the Department of Neuropsychiatry, the University of Tokyo, and an associate professor in the Department of Psychiatry and Neuroscience, Gunma University. He is currently the professor and chair in the Department of Psychiatry and Neuroscience, Gunma University, and his major research interest is clinical neurophysiology and neuroimaging in psychiatry. Kiyoto Kasai received his MD degree in 1995 and his PhD degree in 2004 from the University of Tokyo, Japan. After clinical training in psychiatry at the University of Tokyo Hospital and National Center of Neurology and Psychiatry, he received clinical research training in neuroimaging in psychiatry at Harvard Medical School. He is now the professor and chair in the Department of Neuropsychiatry, the University of Tokyo, and his major research interest is clinical neurophysiology and neuroimaging in schizophrenia. Hideaki Koizumi joined Hitachi, Ltd. in 1971 after receiving his BA degree from the University of Tokyo [PhD (physics), 1976]. He is a fellow and corporate officer of Hitachi, Ltd., a vice president of the Engineering Academy of Japan, a member of the Science Council of Japan, and a foreign member of the Chinese Academy of Engineering. He has proposed many new concepts in human security and well-being and methodologies, especially in the field of spectroscopy. Masashi Kiguchi has studied various optical measurements: nonlinear spectroscopy, time-resolved spectroscopy, near-field spectroscopy, and near-infrared spectroscopy, and his background is physics and laser spectroscopy. He has studied the problems related to the principle of near-infrared spectroscopy (NIRS) measurement and has been taking the lead in the development of new techniques for observing brain activities to open new research fields and in basic studies for putting them to practical use. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||




